Building an Agentic Platform for a Midsized Construction Firm
Reflecting on what I've done and learned thus far, and what that means for the future.
Last revised:
written by: Declan Kramper
tldr/highlights:
- we can all agree there's an opportunity to apply AI to solve problems for SMBs/Mid-market
- while building, the company/partner and I were always clear on goals/priorities and would meet at least 1-2x week to constantly ship and iterate fast
- we already built a tool that works E2E for one subcontractor, w 85% time savings (~$96k/yr using base assumptions); the final 10% is productization for multiple clients/subcontractors
- the first external validation is scheduled: feb 25th with a $300M+ revenue, 300+ employee construction firm
- the key takeaways i've had thus far are:
- reconfirming that iteration speed is how you win (in life, in software. always has been, always will be)
- there's many creative ways to get feedback for those iterations (not just production code)
- the ontology artifact i'm building is the most valuable and enduring asset
- to see a cool hybrid internal dev + client-facing feedback collection tool i made to help with all three of those takeaways, go here
- i see a future where
- AI allows for the "niche-ification" of businesses
- and those that best (+ fastest) translate business knowledge and changing customer needs into value/outcomes will succeed
0. The Opportunity
There's a quote we all know by Bobby Unser, "Success is where preparation and opportunity meet." In business, one of the factors of opportunity is market timing.
Today, businesses of all sizes know that AI can help, but they don't know how. This is especially true of small-to-midsized businesses which don't have the capital, engineering teams, or bandwidth to figure it out. For most of these 5.5 million companies in the US, the $20/mo subscription to ChatGPT isn't doing it because that single tool isn't sophisticated and personalized enough to meet the unique needs of the problems they'll experience tomorrow morning.
There's a gap between the current capabilities of AI models and what these businesses have access to. AI makes it possible to provide them with the software tooling that has historically been out of reach. They just need something to get them across the gap.
Luckily, the work I've been doing for the past two years addresses the other side of Bobby's equation: preparation. I've been studying what it takes to build great products, staying on the cutting edge of new technologies to understand their capabilities, and experimenting by building my own products. Going 0->1 is a messy process, but with repetition, it gets easier.
So when I was put in contact with the owner of a midsized construction firm who wanted his business to be on the cutting edge and explore ways AI can help, I was excited. But the hard questions had to be asked first: what was the business experiencing that was really a problem? what would be the impact if it was solved? would building the solution be worth it?
That's where the other related, but lesser-known, quote from Thomas Edison comes in, "Opportunity is missed by most people because it is dressed in overalls and looks like work".
So, there was only one thing to do: get to work.
1. The Problem
SMBs are already underserved by software and the construction industry within it lags behind even further. There are ~32,000 specialty trade subcontractor firms in the US with 20-300 employees that sit in a dead zone where they're large enough that the complexity of admin work demands purpose-built tooling, but the software available is either Google Drive or priced/built for large enterprises. When talking with the team during the first discovery call, here's what I found:
Subcontractors receive 300+ page, multi-volume specification documents for every project they are called to bid on. A project manager at a ~50 person firm would need to:
- Read through all those pages to figure out what's in their scope
- Match those scope items to the specific pay items they're bidding on
- Identify the exact products that meet the requirements called out in the specs (and double check the engineering estimates so they don't get burned)
- Submit RFQs to vendors for those products
- Juggle quotes from various vendors to find the best price for each product to submit the bid package
- On confirmation of the bid, find datasheets from manufacturers for those products
- Build submittal packages for architect/owner approval that include the datasheets and other documentation called out from the spec books
- Track those approvals
- Generate purchase orders for approved products
- Manage procurement of those materials to ensure quotes are correct and track with what's used in the field
Today, this is all manual. Reading the PDFs, copying into spreadsheets, cross-referencing between documents, Googling product datasheets, creating packages over and over. We can't build to solve all of this all at once. To figure out where to start, we prioritized against two key marks:
- immediate $ impact on his current workflow
- unique offering (not addressed by competitor tooling or the focus of bigger players with more money)
This made sure what we were building was going to be something differentiated and uniquely valuable
For a single project, the submittal process alone takes 2.5 hours. Multiply that by 40 submittals per project & 35 projects a year, and you're looking at project managers spending thousands of hours per year on submittals alone. The competitive and existing tooling research found that most big players were focused on takeoffs and estimations from blueprints, not the project management workflows. The smaller players that did address this space for our target customer of ~50 person firms weren't using AI or building with an AI-first mindset, so the structure they provided was nice, but the workflows were still manual.
These initial numbers and research led us to investigate the submittal process for the first prototype/build scope.
2. The Process
Product discovery & First Prototype
Throughout the product discovery process, we ensured two things were always true
- Clear on our goals
- Building the smallest version to work toward those goals, test/learn, and repeat
From the beginning, we had ambitions to turn the solution into a productized offering that could be sold to others. The process for doing so was to simply make it work for the client's business first and then onboard the others to do the same, with each iterative onboarding capturing the tail ends of requirements until it could be positioned as a self-serve product. The overarching goals were therefore to
- build something that worked for the first subcontractor ->
- build something that be sold to others
Those goals required the business case math to check out. Since this product had to make money, we did one final "is this worth it" check - business model math to determine if this met goal #2. The math is as follows:
Annual Savings ($) = Projects_per_year × Packages_per_project × Hours_per_package × Loaded_hourly_rate × Time_reduction
with base assumptions of:
- 30-40 projects/yr
- 30-50 submittal packages/project
- $50/hr wage for the PM
- 2.5h/package
A conservative 40% time savings on just that submittal workflow, that's $45k/yr in labor savings for our target firm size.
If we charged $500/mo, the subcontractor would pay 13% of the value they get back = a 7.5x monthly ROI. For a firm doing ~$10M in revenue, $500/mo is $6k/yr, or 0.06% of revenue. That's an easy business decision (assuming switching costs are low) for approval with the industry-standard software spend being <1% revenue.
Since the submittal process was the smallest version that delivered the core value of what we were looking for and the math checked out, we started there.
The first focused session was a 90 minutes requirements deep dive on the submittals process. For this session, I came prepared with a board that pieced together what I already knew to be true from initial conversations but outlined the key gaps and questions that would block me from developing the first prototype.
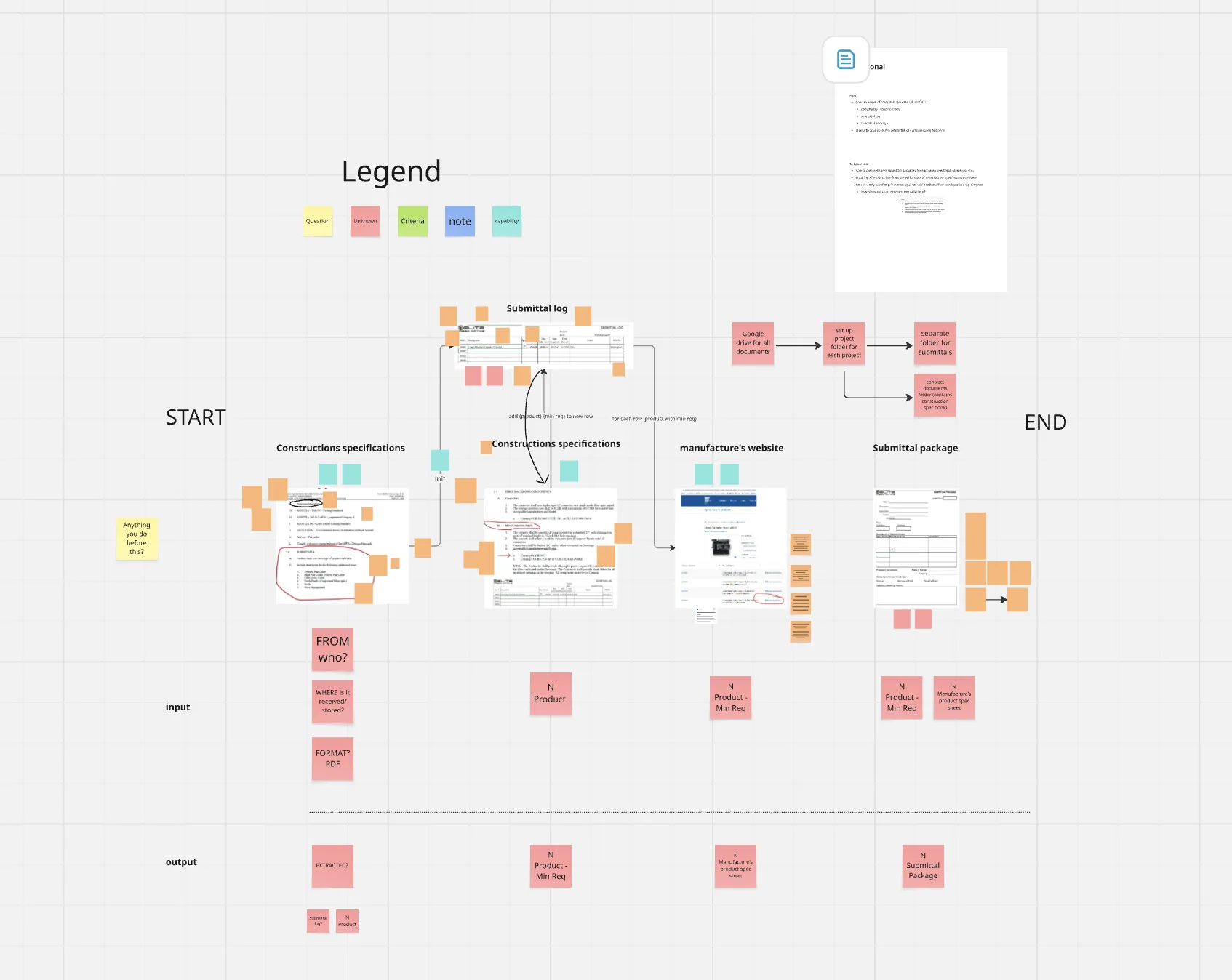
Miro board from the 90-minute requirements deep-dive session.
Using the requirements out of that session, I then went into build mode and delivered the first prototype within two weeks. In these first two weeks I learned a lot of the fundamentals of how to build agent systems and work with LLMs on complex, multi-step problems. I had done work in the past with LLMs in products, but here I dove deeper into how the different agents' SDKs worked (the building blocks of orchestration, context/memory, instructions/permissions, tools, and guardrails). I'll go deeper into this and more later in the piece when I talk about learnings.
Coming out of this build block (which of course included feedback during the process), there was a prototype that (1) recommended scope-items based on the subcontractors trade and (2) sourced data sheets from the web based on the requirements of the confirmed items. No other product on the market did (2). We were then in agreement that this had potential.
Elite v0.1 prototype demo.
But then the question becomes, where do we go from here? The key hunch we had was that
- although this is a promising prototype, we weren't confident that it would be totally competitive as a standalone subscription
- part being, the inputs for the submittal process are decisions and information that the PM would already have figured out by that point, so it would be annoying and redundant to re-confirm the products they were bidding on
The answer to this (although brutally honest) was clear: we had to offer a full end-to-end solution that would serve as the place PMs would go to start their back-office workflows and use through the submittal process. Since we already needed to figure out what their scope was to do the submittal process, if we could build the infrastructure to support the full end-to-end process, this would be a too-hard-to-ignore product that would solve more than just the submittal problem. We're calling this a "spec-to-procurement" platform. This reevaluation of what the product should be and do required us to become clear on the problem statement before moving forward.
Problem Statement:
Project managers for subcontractors ($10M, ~50ppl) have messy, fragmented, and manually-intensive work for managing the E2E submittals and procurement process. Tasks like determining scope, creating RFQs for quotes, and then managing quotes, product approvals, and purchase order tracking have three core problem pillars:
- Messy: ad-hoc templates rebuilt from scratch each project, no standardized format leading to missed items, tribal knowledge that doesn't transfer between projects
- Fragmented: using disconnected documents requiring manual synchronization from previous work, context scattered across tools and decisions without full project context, information in separate files needing to be mentally(manually) stitched together
- manually-intensive: large documents (pdfs/specs) requiring labor-intensive extraction + manual research to match requirements to products/vendors + time spent low-value data entry to compare invoices and catalog inventory
The general hypothesis we were now going to test is:
If a platform handles scope -> bid prep -> submittals -> procurement tracking in one flow, with automation for document and comparison-heavy tasks, and is priced for small/mid subcontractors, then PM teams will adopt it as a default project-start and repeat-use system.
Since this was a bigger undertaking, we also needed to get more specific on our goals and what success looked like for the product. So we asked more questions using pre-mortem frameworks.
| Top risks / assumption to test | Critical question to validate |
|---|---|
| Time savings won't be worth learning or paying for new software | "How much time did you actually spend on finding requirements and running submittal/procurement admin on the last project? Show me." |
| Fragmentation is annoying but tolerable (not painful enough to switch) | "What's the worst thing that happened from a missed submittal item?" |
| PMs/owners won't change their existing workflow | "How did you start your last 3 projects, exactly, and what would have to be true for you to switch?" |
This led us to the three main success metrics we used to prioritize opportunities going forward:
- Adoption: PMs reach for this platform when starting their next project
- Functional retention: PMs repeatedly return and can run the submittal/procurement flow end-to-end without blockers
- Impact ($): reduce PM admin time (targeting up to 85% on validated workflow slices) and increase projects handled per PM
On-going Development + Continued Discovery
I won't spend too much time here since most of the meat in the initial process was figuring out how to go from nothing -> something with clear goals and priorities. We're there. Now that we're there, we'll continue to do what great teams do:
- build in small steps (i frame them as "problems to solve")
- ship early and often (every time we meet, there's something the user/stakeholder can "react to" - whether it's production code, an interactive mockup in the playground, or a document of "rules" to fill out)
- → learn fast (i encode everything into an ontology artifact, more on this in the next section)
- repeat
note: see the lessons learned section for most the key points from this time
3. The Result & Next Steps
Result
In terms of tangible results, what we've accomplished so far is:
- proven time savings of 85% on the submittal process workflow (2.5hr -> 22min)
- an E2E prototype that works across the entire spec-to-procurement workflow
End-to-end demo on loop. Click the dots to jump through each step.
Those two measly points seem to underestimate the amount of work that has gone into this over the past 2months+. They certainly don't include the learnings we'll take away from this. But value in business comes down to one thing: $.
Next Steps & Where We Are Now
The next steps to get there are to finish the last 10% that turns this from a working end-to-end prototype for one subcontractor into a repeatable product for multiple firms. That 10% is where all three success metrics are won in practice: adoption (a tool PMs reach for when starting their next project), functional retention (they keep coming back through key steps), and impact (up to 85% admin-time reduction with increased project load per PM beyond the current ~1.5 concurrent projects).
We already have a forcing function for the final 10%: on February 25, 2026, we're running our first external demo with a $300M+ revenue, 300+ employee construction firm in an adjacent segment. That timeline is tight by design. It forces prioritization and will serve as a true test of portability beyond the initial client and gives us concrete feedback on how this tool needs to adapt to other teams' workflows.
There are two main product problems standing in our way:
1) Finalizing the edge cases of the business ontology
Every business has implicit knowledge and rules with "well, it depends" moments and secondary conditions - to name a few complexities that make modeling a business hard. A rigid product that codes for only the happy path won't survive these moments. The good news is that AI lets you build for solving goals instead of hardcoding every minute action one at a time. The hard part is understanding every detail that would influence a decision so the AI has enough context to accomplish that goal without guessing.
How I'm handling this during development: I treat an ontology artifact as the single source of truth for the entire product. The ontology is actually two separate files:
- Human-readable ontology: a document I can read and understand that links to the exact source (direct quotes from stakeholder calls, spec documents, vendor catalogs) that informed each rule or decision. It keeps a revision log so I can see what changed, when, and why — which matters for visibility and backwards compatibility as the product evolves.
- Codified ontology: formal entities, types, relationships, and IDs that the implementation follows as a contract throughout the codebase. If the code doesn't match the codified ontology, the code is wrong.
After every stakeholder call, the notes I take and the notes from the AI meeting note-taker are cross-referenced against the ontology to find discrepancies and expand or change it based on new learnings. The agents' instructions (via AGENTS.md) have explicit directions to always check the ontology before making changes to the product.
This is the most valuable asset I'm building. The structured understanding of how a construction subcontractor runs their back-office workflows. The code will change. The models will get better. But the codification of how this business actually works will endure. Imagine handing this ontology to a model in three years when it's 10x more capable.
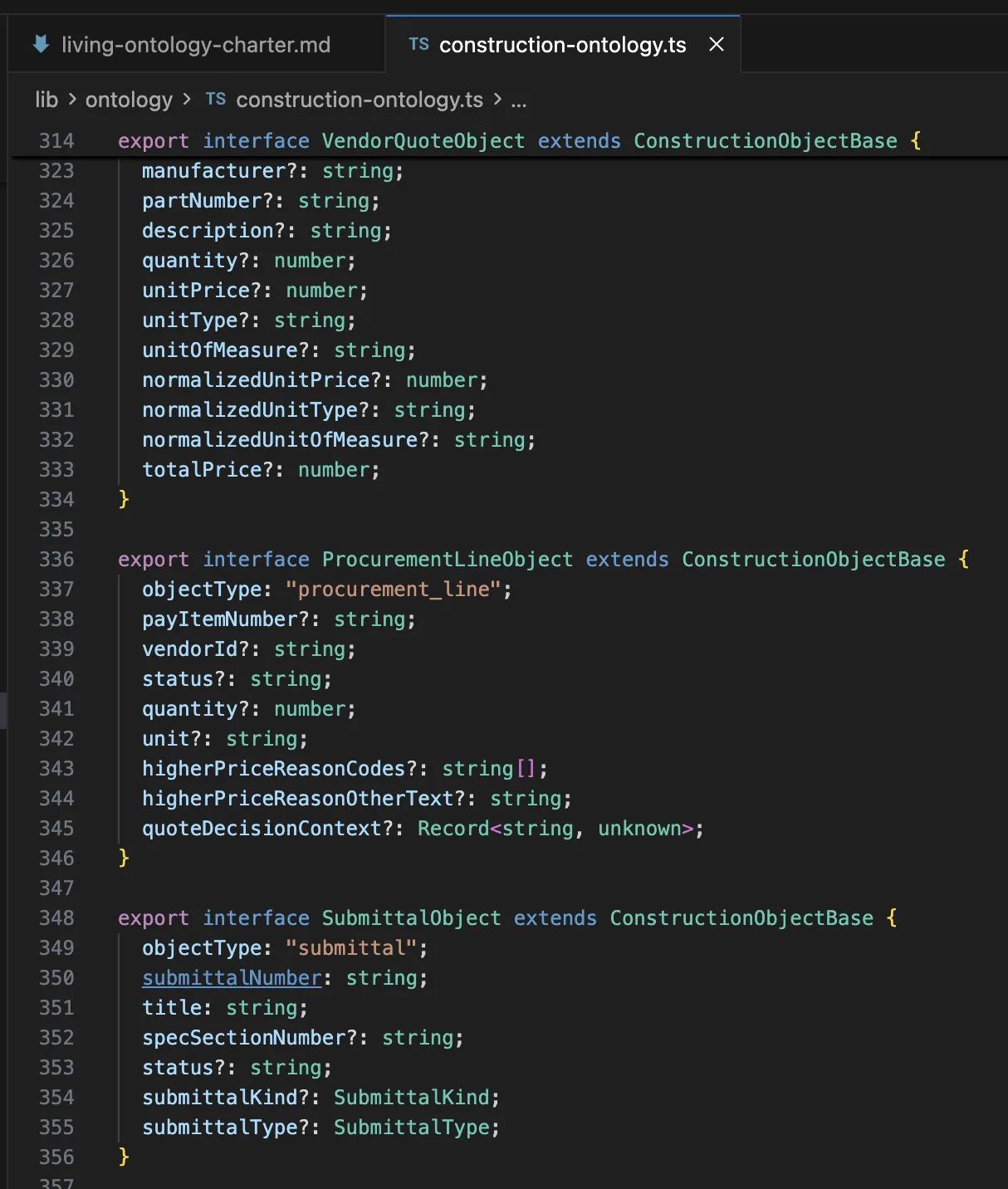
Snippet of ontology contract in code
2) Intuitive product experience
Right now the product is ugly. Like super ugly. Hard to understand. It's fully functional - the AI extracts scope, identifies products, sources datasheets, tracks procurement, etc. But even the main stakeholder I'm building with has a hard time understanding what each output means and what step comes next. If the person I'm building with struggles, no one else is going to pick it up on their own.
This is a design problem, not an AI problem. The AI can extract 30 pages of relevant scope items from a 400-page spec, but if the user can't quickly scan those results, confirm what's right, fix what's wrong, and move on, the extraction doesn't matter. The interface has too much text, the distinction between material and non-material items is confusing, and the relationship between steps isn't clear enough visually. This is mainly a consequence of building really fast in a way that's easy for me to debug.
How I'm solving this: fast iterations using a "feedback playground" I built. It's a separate environment where I create multiple UI variations for a specific design problem, host them at a shareable link, and let the PM click through each one and leave inline comments directly on the elements. Each playground is scoped to a small unit of work and framed as a "problem to solve" one problem (e.g. "how should the scope confirmation screen work when there are multiple products under a single pay item?").

'Feedback playground' tool that scaffolds "problems to solve" into high-fidelity interactive playgrounds for async client feedback.
The need to create a tool like this came out of a time constraint (funny how accidents and constraints happen, isn't it? I'm learning that ideas are actually the outputs of work, not the input). We can't always be on a call (both of us have full-time obligations) so a lot of testing has to happen asynchronously. The highest fidelity form of testing is sitting next to the user while they use it, but since I can't be truly forward-deployed right now, I had to come up with other ways. With this tool, the PM tests variations on his own time, his comments become direct input for the implementation plan.
Think of it as Figma + a dev environment + A/B testing + product analytics from first principles. I see it growing into something with click tracking and time-on-task logging so that even async sessions generate quantitative data on top of the qualitative comments. But for now, the inline comments alone have been useful in moving forward with design decisions.
A time constraint is often a good constraint for cutting through the bullshit and focusing only on what actually matters. This is one of those cases.
4. Lessons Learned (building AI products)
Product
The most valuable thing I'm building is the ontology: I mentioned this above, but it's worth saying again as a lesson because I didn't think this way at the start. I thought I was building a product. What I'm actually building is a structured representation of how this business works that happens to power an product. The ontology is what makes the AI useful. Everything will be ran by AI in the future, so the data (the data in this case = what I'm calling the business ontology) is the moat. This is especially true considering how exponentially easier AI is making it to produce software.
I took the current BAU process too literally at first: It's good to meet customers where they are in their existing tools and workflows. And you should definitely be doing that. But some of the product design problems I'm experiencing are because I'm trying adapt AI (a totally new way of working) to their existing manual sequences. If they had AI from day one, how would this process look then? So that experience is what I'm trying to build now. That reframing gave me permission to consider layouts, flows, and ideas that would never come from just replicating the current BAU.
Frame issues as "problems to solve" and work backwards from the ideal state: I had a very difficult time trying to architect the full ingestion and extraction pipeline (lots of architectural and product decisions tangled together to meet the domain expectations). Instead of framing it as an issue because it's a large undertaking, I framed it as a problem to solve. "Okay how am I going to go about solving this problem of how to conduct the scope discovery process?" "What's the output we need at the end of this step to move forward?" After understanding that end ideal state, you work backwards from there. It's more fun to think this way. It also helped narrow in on the key item I needed for this situation, which was identifying the material scope, because that's what drives the bidding process.
Make it lower fidelity to make it faster: Feedback doesn't have to be a synchronous video call. A screen recording, an interactive document with fill in the blank and multiple specific questions, or a feedback playground link all generate signal/feedback. You must be okay with shipping imperfection (spoiler: it will always be). The natural urge is to wait until the code is "ready" to show someone. The better route is to optimize for the reaction/signal that will unblock whichever problem you're currently on.
Think in terms of experiments: Framing the "problem to solve" as a clear problem with a measurable impact if not solved, and hypothesis on what is causing the problem, with what you'd expect if the problem is solved, and then ranked tests/experiments for changing one thing at a time and tracking the output against the expected signal (better/worse with notes so its a log of learning) is a great way to structure both your's and the model's thoughts.
Technical architecture
For broader notes on coding with AI, see my blog post
Deterministic workflows with LLM-powered steps, then transition to agentic: For processes where you don't know the exact rules of the business (e.g. starting from scratch like I am here), don't let the AI orchestrate. Observability tools for these models are still early, and steering an agent when you don't even know exactly where you should be steering it is driving blind. You can't get feedback on what you're building because you can't see why your product made those decisions. Start with a deterministic, human-orchestrated workflow: the human triggers each step, the AI does the work within that step, the human reviews and moves forward. Once you've codified the business rules and proven the workflow, then you can start handing orchestration control to the agent. It'll still look like an agent to the user. It just knows when to stop. Another way to say this is AI prepares decisions, human makes it.
Fix context, not code: When the AI gets something wrong, the instinct is to add a conditional, hardcode an exception, patch the output. But most of the time, the real problem is that the model didn't have the right context to make the right decision. Better instructions, better examples, better-structured input data is where you should be thinking. These improve the output today and in the future when the models get better. This mindset shift, treating failures as context problems rather than code problems, has been one of the biggest unlocks in how I build.
Build lightweight scaffolding you're ready to throw away: Future models won't need the current infrastructure. The vector stores, chunking strategies, multi-step validation loops that feel essential today will be obsolete as models improve. So make everything atomic and accessible. Anything the user can do through the UI, the agent should be able to do too. Keep the business logic cleanly separated from the AI reasoning. I'm structuring things so that as models get faster and more capable, more of the rigid orchestration can be removed while still allowing the model to achieve the end goal. The next model release makes the product better, not breaks it.
Structured outputs with semantic retry validation: Every AI extraction step that is returning data for an important decision uses JSON schemas so the results are programmatically usable. But I learned schema validation alone isn't enough because a response can pass the schema while being incomplete or wrong in domain-specific ways. So I added semantic retry validation: if an extraction result passes the schema but has null values or low-confidence fields that should have data, the system retries with more targeted context. This catches the "technically valid but actually useless" outputs that schema validation misses.
Use determinism where it's certain, but give freedom where the model can learn: Hard regex filters for things the user explicitly wants to block? Deterministic and fine. But for the pools of information where you have to include everything, you can't use determinism because you can't capture it all. Give the model the room to reason in these scenarios. The models are already smart and improve faster than you can hardcode logic. The goal is to remove the rigid scaffolding as fast as you can verify the model handles it comparably, because spending extra time perfecting hard-coded rules is a losing bet against next month's model release.
Surface progress, not just final output: User feedback has been really receptive to any feature that shows model progress as it happens and evidence for what it's thinking.
RAG with page-level grounding: With AI outputs, the users only truly trust what they can actually point back and see on the actual page/source. I built a retrieval pipeline that chunks by page, embeds for semantic search, but always links back to the original text and page number. This is different from just using a file search API where the citation is model-generated and untrustworthy. With this approach the evidence is deterministic because it traces directly to the stored page content and I'm able to deep-link back to the source.
Consulting basics
Specific questions get specific, actionable answers: This is obvious but it's important I keep reminding myself. The questions I come up with while building - the ones that are actually blocking me from making progress - are 10x more useful in a stakeholder call than asking the AI to generate a list of discovery questions. Those AI-generated lists are always bloated and generic. The questions I prepare myself are specific, contextual, and lead to answers I know how to immediately act on. (will this reverse in the future? maybe. but not the case today)
Get as much data upfront as possible: There was a point where I was struggling to figure out how to architect the AI to complete a task with what I thought was the full extent of information available to the user at that time in their workflow. I was actually operating with incomplete information. I should have followed up aggressively to make sure I had every document needed to understand the full picture before building. The hardest part of building for a client is getting the information out of their heads and understanding what actually matters. A reminder to myself to push extra for it early to save time.
Show up: Every week, we meet. Every week, I ship something. Every week, I learn. Life happens to those who show up.
5. Closing Thoughts
For this project, the path forward is clear: finish the last 10% that moves this from an effective single-client implementation to a product that consistently works across various subcontractors. We already have an E2E system that works; now we're productizing it for broader adoption against the same success metrics. Each new onboarding captures the tail ends of requirements until it can stand on its own as a self-serve product.
The February 25, 2026 external demo with the $300M+ revenue, 300+ employee construction firm is the forcing function for this phase. If a second firm in an adjacent construction segment can see themselves using it and gives us concrete feedback on where it fits or breaks in their process, that's the signal that this is becoming a credible product, not just a promising internal prototype.
For other projects, the same process works. Find the person who knows the work, sit with them, build the tool, test it on their real projects, iterate fast. Anywhere the work is real but the software hasn't caught up is prime. I plan to do it again.
The two problems I'm most focused on going forward are the same two standing in the way of finishing this product:
- Extracting and encoding business ontology faster. This is the bottleneck right now. It's true in any project where a real business tries to apply AI. The gap between "the model can do it" and "the model knows enough about your business to do it right" is where all the hard work lives. I've started building an open-source project called ontology-xtract to explore how agents can systematically uncover and encode business knowledge. I'm first imagining it as an agent that can run the initial "applied AI discovery call" of any engagement. It'd use all my practical learnings from having applied in real situations. And then maybe it could be used for in-flight work too (an extension of the feedback playground).
- Shortening the feedback loop between what the user needs and what the product does. The playground is one tool for this. The next iteration of ontology-xtract could be another. But the principle is the same: the fastest cycle from conversation to working software wins.
These two things connect to something I've been thinking about for a while. In early 2025, I gave a presentation to my colleagues at Publicis Sapient about AI and the future of product management. My thesis was that because Product Managers are (1) supposed to best understand the most important stakeholder in any business (the customer) and (2) that they sit in the middle between the customer's need and the business delivering value, then therefore they are best positioned to excel in the post-AI world where the ones who are able to shorten the loop from 'conversation' to 'working software' will build the winning products. I believed it then, and it's become more true everyday. Every week building with AI to deploy AI on this project is an example of that.
On what these means for the future of companies: I think AI enables a future where more niche businesses can operate efficiently and sustainably. The barriers to building software for a 50-person fiber optics subcontractor used to be too high -- the market was too small, the domain too specialized, the development too expensive. That's changing. And the companies that win in that future will be the ones with the deepest expertise and the shortest cycle from changing customer needs to delivered value.
Creating a better world, is better, right?